프로그램은 하드디스크 같은 저장장치에 보관되어 있는 정적인 상태를 의미
프로세스는 프로그램이 실행되어 메모리에 올라온 동적인 상태를 의미
CPU가 타임 슬라이스를 여러 프로세스에 적당히 배분함으로써 동시에 실행하는 것처럼 보임
프로그램에서 프로세스로의 전환
프로세스는 컴퓨터 시스템의 작업 단위로 태스크라고도 부름
1. 운영체제는 프로그램을 메모리에 적재하고, 프로세스 제어 블록(PCB, Process Control Block)을 생성
- PCB는 운영체제가 해당 프로세스를 관리하는 데이터 구조이기 때문에 메모리의 운영체제 영역에 만들어짐
- 운영체제도 프로그램이므로 프로세스(커널 프로세스)로 실행되기 때문에 PCB가 있음
2. 프로세스가 종료되면 프로세스가 메모리에서 삭제되고 PCB도 폐기됨
프로세스의 상태
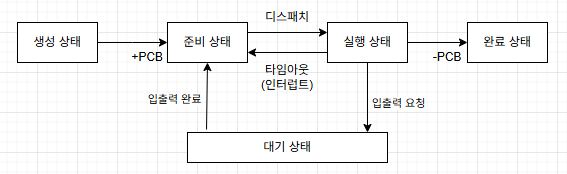
생성 상태
프로세스가 메모리에 올라와 실행 준비를 완료한 상태
운영체제로부터 PCB를 할당받은 상태
준비 상태
생성된 프로세스가 CPU를 얻을 때까지 기다리는 상태
CPU 스케줄러가 준비 상태의 프로세스 중 하나를 실행 상태로 바꿔 CPU에 PCB를 전달하는 작업을 디스패치라고 함
실행 상태
준비 상태에 있는 프로세스 중 하나가 CPU를 얻어 작업을 수행하는 상태
타임 슬라이스 동안 CPU를 사용할 권리를 갖고, 작업이 끝나지 않았다면 준비 상태로 돌아와 CPU를 얻기 위해 기다림(타임아웃)
CPU는 타임 슬라이스가 지난 뒤 클럭이 인터럽트를 전송
대기 상태
입출력을 요청한 프로세스가 입출력이 완료될 때까지 기다리는 상태
효율을 높이기 위해 입출력을 요청한 프로세스가 대기 상태가 되면 CPU 스케줄러는 준비 상태에 있는 프로세스를 실행함
입출력이 완료되면 입출력 관리자로부터 인터럽트를 받아 대기 상태로 전환, 만약 실행 상태로 전환한다면 현재 진행 중인 프로세스를 중단해야 하므로 복잡하기 때문에 대기 상태로 기다림
인터럽트가 들어왔을 때 효율적으로 프로세스를 찾기 위해 같은 입출력을 요구한 프로세스끼리 모아 놓음
완료 상태
실행 상태의 프로세스가 작업을 마친 상태
코드, 사용했던 데이터, PCB를 메모리에서 삭제
만약 오류나 다른 프로세스에 의해 비정상적으로 종료된다면 디버깅하기 위해 종료 직전의 메모리 상태를 저장장치로 옮기는데 이를 코어 덤프라고 함
PCB(프로세스 제어 블록)
프로세스를 실행하는 데 필요한 중요한 정보를 보관하는 자료 구조
보통 커널 내에 프로세스 테이블의 형태로 관리됨
모든 프로세스는 고유한 PCB를 가지며, 프로세스 생성 시 만들어지고 실행을 완료하면 폐기됨
PCB 구성

포인터 : PCB를 연결하여 프로세스의 준비 상태나 대기 상태의 큐를 구현할 때 포인터를 사용
프로세스 우선순위 : CPU 스케줄러가 준비 상태에 있는 프로세스 중 실행 상태로 옮겨야 할 프로세스를 선택할 때 프로세스 우선순위를 기준으로 삼음
각종 레지스터 정보 : 프로세스가 실행되는 중에 사용하던 레지스터 값들이 저장하여 다음에 실행할 때 저장된 레지스터 값을 사용
메모리 관리 정보 : 프로세스의 메모리 주소를 나타내는 메모리 위치 정보, 메모리 경계 레지스터 값과 한계 레지스터 값, Segmentation Table, Page Table 등 저장
할당된 자원 정보 : 프로세스를 실행하기 위해 사용하는 입출력 자원이나 오픈 파일 등에 대한 정보
계정 정보 : 계정 번호, CPU 할당 시간, CPU 사용 시간 등
PPID(Parent PID), CPID(Child PID)
Context Switch(문맥 교환)
기존 프로세스를 종료하고 새로운 프로세스의 실행을 준비하는 과정
기존 프로세스의 PCB에 작업 내용을 저장하고, 실행하는 프로세스의 PCB 내용으로 CPU를 설정
프로세스에 할당된 타임 슬라이스를 모두 사용한 경우, 인터럽트가 발생하여 인터럽트를 처리하는 경우 등에 컨텍스트 스위치가 일어남
잦은 컨텍스트 스위칭은 캐시 미스가 발생할 가능성이 높아져 메모리로부터 실행할 프로세스의 내용을 가져오는 작업이 빈번해져 큰 오버헤드 발생 가능
- 시스템 콜을 사용하면 사용자 모드에서 커널 모드로 전환하는 과정에서 컨텍스트 스위칭이 발생
프로세스의 구조
프로세스는 코드 영역, 데이터 영역, 힙 영역, 스택 영역으로 구성됨
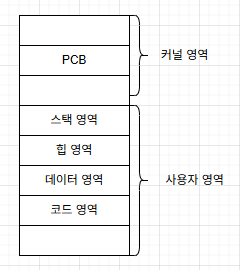
코드 영역
프로그래머가 작성한 프로그램은 코드 영역에 저장됨
읽기 전용(자기 자신을 수정하는 프로그램은 없기 때문)
데이터 영역
프로그램이 실행되는 동안 유지할 데이터(정적(static)/전역 변수)가 저장되는 공간
BSS(Block Started by Symbol) 영역 : 초기값이 없는(0으로 초기화) 데이터가 저장되는 공간
읽기/쓰기가 모두 가능한 영역과 읽기 전용 영역으로 나뉨
힙 영역
프로세스가 실행되는 동안 동적으로 할당되는 영역
스택 영역
프로세스를 실행하기 위해 일시적으로 사용할 값들이 저장되는 공간으로 지역 변수(매개 변수 포함), 함수 복귀 주소 등이 저장됨
프로세스가 실행되는 동안 만들어지는 동적 할당 영역은 레지스터 값, 스택, 힙 등
스레드
프로세스의 코드에 정의된 절차에 따라 CPU에 작업 요청을 하는 실행 단위
(운영체제 입장에서의 작업 단위는 프로세스, CPU 입장에서의 작업 단위는 스레드)
프로세스는 하나 이상의 스레드로 구성됨
하나의 스레드에는 스레드 ID와 프로그램 카운터, 레지스터 값, 스택 등으로 구성
스레드마다 다음에 실행할 주소와 연산 과정의 임시 저장 값을 가짐
프로세스와 스레드의 차이
프로세스는 다른 프로세스에 큰 영향을 미치지 않기 때문에 순서를 바꾸어도 문제 없음
- 서로 독립적인 프로세스는 데이터를 주고받을 때 프로세스 간 통신(IPC, Inter Process Communication)을 이용
스레드는 다른 스레드에 큰 영향을 미칠 수 있기 때문에 순서를 바꾸면 문제가 될 수 있음
(예를 들면 B 스레드는 A 스레드가 끝난 뒤 실행해야 한다면 순서를 바꿀 때 문제 발생)
- 멀티스레드는 변수나 파일 등을 공유할 수 있고, 전역 변수나 함수 호출 등의 방법으로 스레드 간 통신을 함
프로세스 내의 다른 스레드로 컨텍스트 스위칭할 때 다른 프로세스로 컨텍스트 스위칭하는 것보다 빠른 이유는 스레드는 독립적인 스택 영역만 있어 비교적 적은 메모리를 컨텍스트 스위칭하여 적은 캐시 미스, 적은 메모리 접근 횟수, 적은 레지스터 변경 때문
스레드 관련 용어
멀티스레드 : 프로세스 내 작업을 여러 개의 스레드로 분할함으로써 작업의 부담을 줄이는 프로세스 운영 기법
멀티태스킹(시분할 시스템) : 운영체제가 CPU에 작업을 줄 때(스레드에) 시간을 잘게 나누어 배분하는 기법
멀티프로세싱 : 독립적인 여러 개의 프로세스를 여러 개의 CPU 혹은 하나의 CPU 내 여러 개의 코어에 스레드를 배정하여 동시에 처리하는 작업 환경
- 예시 : 네트워크로 연결된 여러 컴퓨터에 스레드를 나누어 협업하는 분산 시스템
(CPU) 멀티스레드 : 한 번에 하나씩 처리해야 하는 스레드를 파이프라인 기법을 이용하여 동시에 여러 스레드를 처리하도록 만든 병렬 처리 기법
멀티스레드 장점
한 스레드가 입출력으로 인해 작업이 진행되지 않더라도 다른 스레드가 작업을 계속하여 사용자의 작업 요구에 빨리 응답할 수 있음
한 프로세스 내에서 독립적인 스레드를 생성하면 프로세스가 가진 자원(코드, 데이터, 힙)을 모든 스레드가 공유
여러 개의 프로세스를 생성하는 것과 달리 불필요한 자원의 중복(중복되는 프로세스의 정적 영역)을 막음으로써 메모리 할당 시간 및 공간 감소
2개 이상의 CPU를 가진 컴퓨터에서 멀티스레드를 사용하면 다중 CPU가 멀티스레드를 동시에 처리하여 CPU 사용량이 증가하고 프로세스의 처리 시간이 단축
멀티스레드 단점
멀티스레드는 모든 스레드가 자원을 공유하기 때문에 한 스레드에 문제가 생기면 전체 프로세스에 영향을 미침
사용자 레벨 스레드
라이브러리에 의해 구현된 일반적인 스레드
운영체제가 멀티스레드를 지원하지 않을 때 사용하는 방법으로, 초기의 스레드 시스템에서 이용됨
사용자 레벨에서 스레드를 구현하기 때문에 관련 라이브러리를 사용하여 구현하며, 라이브러리는 커널이 지원하는 스케줄링이나 동기화 같은 기능을 대신 구현해주기 때문에 커널 입장에서 하나의 프로세스처럼 보임
따라서 사용자 프로세스 내의 여러 스레드가 존재하지만 커널의 스레드 하나와 연결되기 때문에 1 to N 모델이라고 부름
라이브러리가 직접 스케줄링을 하고 작업에 필요한 정보를 처리하기 때문에 문맥 교환이 필요 없어 속도가 빠름
(서로 다른 프로세스를 동시에 실행하지 않기 때문)
여러 개의 스레드가 하나의 커널 스레드와 연결되기 때문에 커널 스레드가 입출력 작업을 위해 대기 상태가 되면 모든 사용자 레벨 스레드가 같이 대기 상태가 되는 단점
한 프로세스의 타임 슬라이스를 여러 스레드가 공유하기 때문에 여러 개의 CPU를 동시에 사용할 수 없는 단점
기능을 커널이 아닌 라이브러리에 구현해야 하기 때문에 보안에 취약
커널 레벨 스레드
커널이 직접 생성하고 관리하는 스레드
커널이 멀티스레드를 지원하는 방식으로, 하나의 사용자 스레드가 하나의 커널 스레드와 연결되기 때문에 1 to 1 모델이라고 부름
독립적으로 스케줄링이 되므로 특정 스레드가 대기 상태가 되어도 다른 스레드는 작업을 계속할 수 있음
커널이 제공하는 보호 기능과 같은 모든 기능을 사용할 수 있음
커널 레벨에서 모든 작업을 지원하기 때문에 멀티 CPU를 사용할 수 있음
스레드(혹은 프로세스) 전환이 발생할 때 문맥 교환으로 인한 오버헤드 때문에 느리게 작동
멀티레벨(하이브리드) 스레드
사용자 레벨 스레드와 커널 레벨 스레드를 혼합한 방식으로 M to N 모델이라고 부름(M >= N)
하나의 커널 스레드가 대기 상태가 되면 다른 커널 스레드가 대신 작업하여 사용자 레벨 스레드보다 유연하게 작업을 처리할 수 있음
커널 레벨 스레드를 같이 사용하기 때문에 여전히 문맥 교환 오버헤드가 있어 사용자 레벨 스레드만큼 빠르지 않음
따라서 빨리 작업해야 하는 스레드는 사용자 레벨 스레드로 작동하고, 안정적으로 작업해야 하는 스레드는 커널 레벨 스레드로 작동함
'CS > 쉽게 배우는 운영체제' 카테고리의 다른 글
| [쉽게 배우는 운영체제] 5장 프로세스 동기화 (0) | 2025.02.24 |
|---|---|
| [쉽게 배우는 운영체제] 4장 CPU 스케줄링 (0) | 2025.02.19 |
| [쉽게 배우는 운영체제] 1장 운영체제 개요 (0) | 2025.01.31 |
| 운영체제 중요 항목 (1) | 2024.09.29 |
| 운영체제 파일 시스템 (0) | 2024.09.29 |








